
9. On-Policy Distillation:图解速览(外部资料汇编)
Published:
A visual companion to blog 8. Image panels collected from an external author’s note (watermarks preserved).
这是 8 号 《On-Policy Distillation》 的图解速览版本——把整理得比较好的图整张保留下来作为对照。
图片来源:小红书 @古希腊掌管代码的神 ·《On-Policy (Self) Distillation 算法总结》(图中右上角水印为原作者署名)。本页仅作个人学习摘录索引使用,所有视觉内容版权归原作者。文字推导请回到 8 号 blog。
1) 背景:SFT 的 dense supervision vs RL 的稀疏 reward
引出 On-Policy Distillation (OPD) 的动机——SFT 是 off-policy 但 dense,RL 是 on-policy 但稀疏,OPD 想同时拿到两边的好处。

2) OPD 与 Sampled-token Reverse KL;Forward / Reverse KL 的分布直觉
OPD 把 student rollout 与 teacher 每个位置的 logit 对齐。下半部分的双峰图给出 forward KL(mean-seeking)vs reverse KL(mode-seeking)的直觉。

3) Full-vocabulary Forward KL;从 OPD 到 Self-Distillation
把 KL 展开到整个词表降低梯度方差;同时引出 self-distillation:用同一模型加不同条件分别充当 teacher 与 student。

4) OPSD:Self-Distilled Reasoner
OPSD 的系统图——dataset 出 prompt $x$ 给 student、prompt $(x, y^*)$ 给 teacher,per-token divergence 只让 student 一侧反传。

5) SDFT(持续学习场景)/ SDPO(用文本反馈作为 teacher 条件)
SDFT 把 self-distillation 用作正则化,缓解灾难性遗忘;SDPO 把 verifier 反馈作为 teacher 的额外条件。

6) CRISP(推理压缩)+ G-OPD / ExOPD 引言
CRISP 给 teacher 加 “be concise” 指令蒸馏到 student,token 数砍半同时准确率反升;G-OPD 引入 reward 缩放系数 $\lambda$。
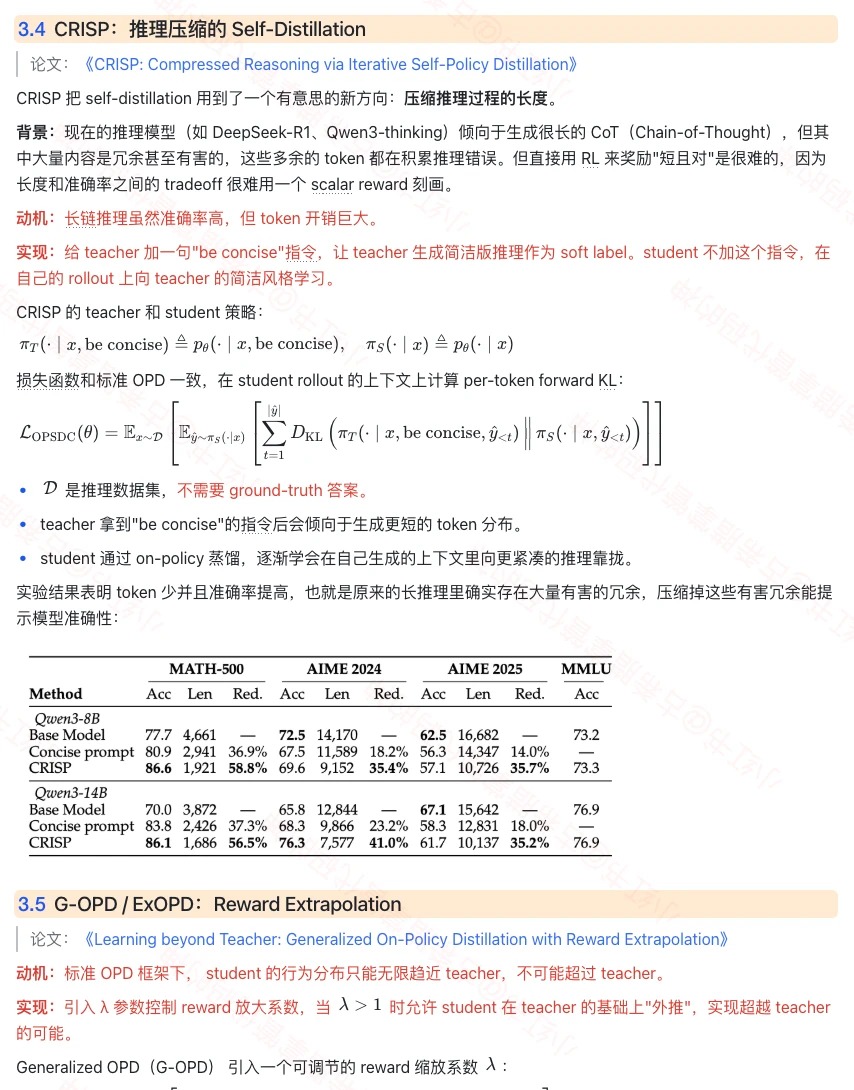
7) G-OPD 公式 / GAD(Black-Box OPD)
G-OPD 的完整 loss;GAD 用 generator-discriminator 对抗训练替代 logit 对齐,是 black-box teacher 场景下唯一可行的路径。
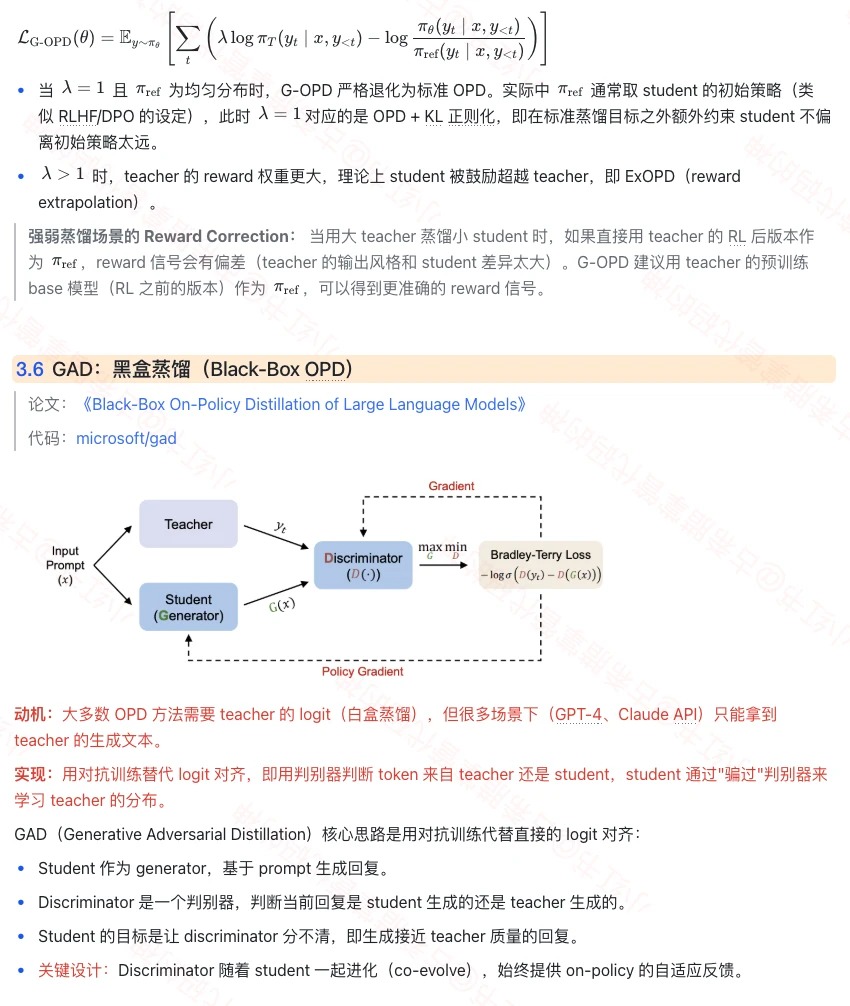
文字版请见 8 号 《On-Policy Distillation》;理论背景见 5 号 《KL Divergence》 与 6 号 《损失函数推导》。